Table 2 Datasets Used to Evaluate Predictors in Table 4 , including the source from which they were derived, as well as the publication in which they were created using the requirements in the “Description” column
From: Algorithmic approaches to protein-protein interaction site prediction
Label | Name | Derived from | Source | Description | Creator | Year |
|---|---|---|---|---|---|---|
A | DB3-188 | DB 3.0 | [77] |
\(\mathcal {S}_{i} < 40\% \); | [31] | 2010 |
B | DS56B | CAPRI | [78] | Targets 1-27 Bound | [31] | 2010 |
C | DS56U | CAPRI | [78] | Targets 1-27 Unbound | [31] | 2010 |
D | NI1 | PDB | [79] |
\(\mathcal {S}_{i} < 70\% \); | [37] | 2014 |
N 100≥1; Excl. Ag-Ab; Non-obligate; MC | ||||||
E | NI2 | PDB | [79] |
\(\mathcal {S}_{i} < 70\% \); | [37] | 2014 |
N 100≥2; Excl. Ag-Ab; Non-obligate; MC | ||||||
F | PlaneDimers | Mintz et al. | [110] | Planar PPI; 20%<MSA i <90%; | [33] | 2011 |
Excl. MBPs, Ag-Ab, VS; | ||||||
* | Dimers | Mintz et al. | [110] | Clustered on seq. similarity; Excl. | [33] | 2011 |
MBPs, Ag-Ab, VS; | ||||||
G | TransComp_1 | DB 4.0 | [108] | “Simple” (low conf. change); Non-obligate | [33] | 2011 |
* | TransComp_2 | CAPRI | [111] | Not in TransComp_1; Non-obligate | [33] | 2011 |
H | W025 | DB 1.0/2.0 | Excl. Ag-Ab, enzyme interactions | [41] | 2006 | |
I | S435 | PDB | [79] | PQS filtered; \(\mathcal {S}_{i} < 50\% \); | [39] | 2007 |
Excl. NA, MBPs, VS, NMR | ||||||
J | S149 | PDB | [79] | PQS filtered; \(\mathcal {S}_{i} < 50\% \); | [39] | 2007 |
NA, MBPs, VS, NMR; N H (S435) | ||||||
* | S21a | S149 | [39] | Nonredundant; MC | [39] | 2007 |
K | S58 | PDB | [79] |
\(\mathcal {S}_{i} < 30\% \); | [7] | 2012 |
Excl. NA, ligands; N H (S435) | ||||||
L | 3DS | 3did | [112] |
\(\mathcal {S}_{i} < 25\% \); | [38] | 2012 |
M | B100 | DB 3.0 | [77] | Excl. Ag-Ab | [40] | 2011 |
N | BM180 | PDB | [79] |
\(\mathcal {S}_{i} < 20\% \); | [13] | 2005 |
NMR; Divided into 4 sub-types | ||||||
* | S1 | PDB | [79] |
\(\mathcal {S}_{i} < 50\% \); 10< | [113] | 2009 |
short; Excl. MBPs, NA; Disprot filtered | ||||||
* | S2 | PDB | [79] |
\(\mathcal {S}_{i} < 50\% \); | [113] | 2009 |
long; Excl. MBPs, NA; Disprot filtered | ||||||
* | DS24Carl | PDB | [79] |
| [66] | 2008 |
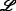 >50
>50 ≤3.5; 100≤
≤3.5; 100≤ - The “Label” column defines the alphabetic character used to refer to the dataset in Table 4. “ ∗” in the “Label” column signifies that the set is not presented in Table 4 as it is not widely used. \(\mathcal {S}_{i}\) is the sequence identity redundancy cutoff,
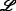 is the amino acid length of the chain,
is the amino acid length of the chain,  is the resolution cutoff in angstroms, N
100≥n requires that the number of interface residues per 100 residues in a given protein to be greater than n, Ag-Ab refers to antigen-antibody complexes, M
S
A
i
is the sequence identity redundancy cutoff for chains in an MSA, VS refers to Viral Subunits, NA refers to Nucleic Acids, N
H
(x) refers to a set being non-homologous to set x, MC denotes that both the monomer and the complex to which it belongs are known.
is the resolution cutoff in angstroms, N
100≥n requires that the number of interface residues per 100 residues in a given protein to be greater than n, Ag-Ab refers to antigen-antibody complexes, M
S
A
i
is the sequence identity redundancy cutoff for chains in an MSA, VS refers to Viral Subunits, NA refers to Nucleic Acids, N
H
(x) refers to a set being non-homologous to set x, MC denotes that both the monomer and the complex to which it belongs are known.